如何爬取微信公众号文章(一)
本文共 8065 字,大约阅读时间需要 26 分钟。
微信公众号是目前最为流行的自媒体之一,上面有大量的内容,如何将自己感兴趣的公众号内容爬取下来,离线浏览,或者作进一步的分析呢?
下面我们讨论一下微信公众号文章的爬取。
环境搭建
- windows 7 x64
- python3.7 (Anaconda 3)
- vscode编辑器
- Firefox开发版
爬虫原理分析
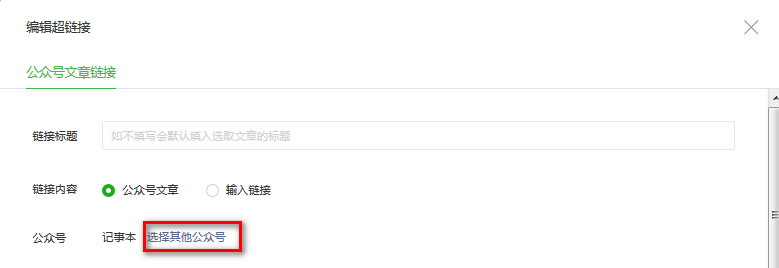
首先网页登陆微信公众平台(https://mp.weixin.qq.com/),登陆成功后,点击新建群发->自建图文,插入超连接在如下的对话框中,点击选择其他公众号。
 在弹出的编辑超链接的对话框中,输入想要爬取的公众号名字,回车
在弹出的编辑超链接的对话框中,输入想要爬取的公众号名字,回车 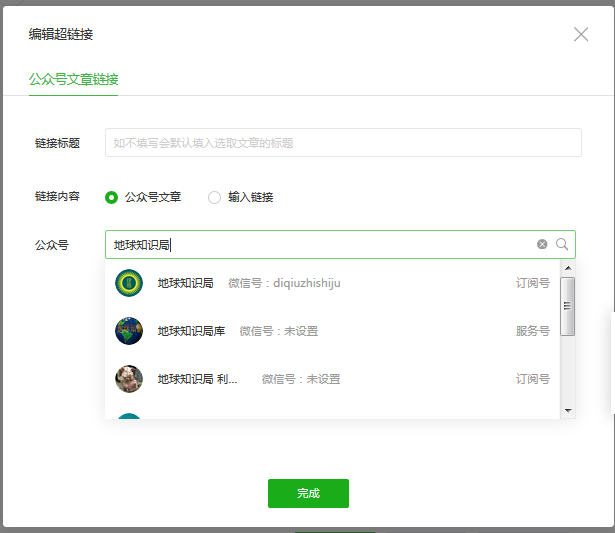 下拉列表中第一个就是我们想找的,点击它,弹出的这个公众号的文章列表,是按照时间排序的。
下拉列表中第一个就是我们想找的,点击它,弹出的这个公众号的文章列表,是按照时间排序的。 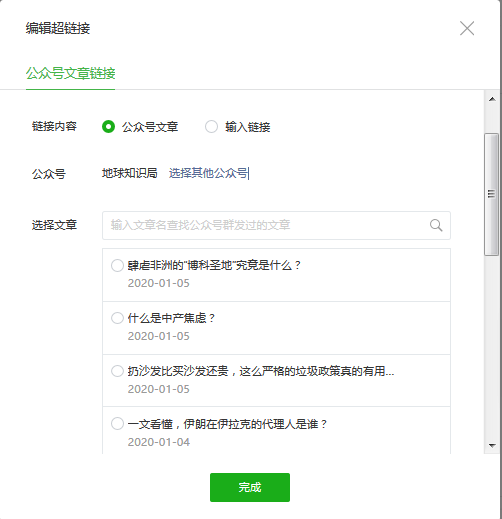 我们看一下这个过程中前后端交互的HTTP请求和响应。
我们看一下这个过程中前后端交互的HTTP请求和响应。 检索公众号
请求url: https://mp.weixin.qq.com/cgi-bin/searchbiz
方法: GET 提交的参数为{ "action": "search_biz", "begin": "0", "count": "5", "query": "地球知识局", "token": "138019412", "lang": "zh_CN", "f": "json", "ajax": "1"} 请求中的字段
action 动作
begin 列表的起始 count 列表的数目 query 查询的字符串 f 参数格式 这里为json ajax 应该代码ajax请求 lang 语言 这里是中文 token 这应该是授权信息,下文会深究
得到的响应为
{ "base_resp": { "ret": 0, "err_msg": "ok" }, "list": [ { "fakeid": "MzI1ODUzNjQ1Mw==", "nickname": "地球知识局", "alias": "diqiuzhishiju", "round_head_img": "http://mmbiz.qpic.cn/mmbiz_png/DCftNYRGoKWLHFETxuTzGBguTwAibl0p8BpXmNIkBTmNth2Vd6vEWibtT8mLYWG6e5aiaa97u5LmjhbXn19a8Cr6g/0?wx_fmt=png", "service_type": 1 }, { "fakeid": "MzU5MjI3MzIyMg==", "nickname": "地球知识局库", "alias": "", "round_head_img": "http://mmbiz.qpic.cn/mmbiz_png/b5kRqlMaRNHJnJ1ibFUPOichbvtVGk7CWicj406ZAccBuOpr2JibShHSAvUN7iaSuQj3rN66P8akeKa63rjy11NNkicw/0?wx_fmt=png", "service_type": 2 }, { }, { }, { } ], "total": 45} 响应中各字段的含义不难看出
fakeid 为该公众号的唯一的id,为一串bs64编码
nikename 为公众号的名称 alias 为别名 round_head_img 为圆形logo的url service_type 服务类型 不太清楚 没必要深究用不到
获取公众号文章列表
请求网址:https://mp.weixin.qq.com/cgi-bin/appmsg
请求方法:GET 提交的参数:{ "action": "list_ex", "begin": "0", "count": "5", "fakeid": "MzI1ODUzNjQ1Mw==", "type": "9", "query": "", "token": "138019412", "lang": "zh_CN", "f": "json", "ajax": "1"} action 行为
begin 列表开始索引 count 列表返回的公众号的时间区间长度,如5表示返回5天的数据 fakeid 这个公众号的ID type 不知道 query 检索的关键字,这里为空 token 用户的token lang 语言 f 数据格式,这里为json ajax
响应为
{ "app_msg_cnt": 919, "app_msg_list": [ { "aid": "2247518136_1", "appmsgid": 2247518136, "cover": "https://mmbiz.qlogo.cn/mmbiz_jpg/DCftNYRGoKWG0USHVfs1FG2pGKfz0BMUI3FLibHTrYe1a7WMKzZnazCKDJ9OUfuibGbewFqIiakic8MEqDkNiaXHH7w/0?wx_fmt=jpeg", "create_time": 1578235906, "digest": "三不管地带容易出问题", "is_pay_subscribe": 0, "item_show_type": 0, "itemidx": 1, "link": "http://mp.weixin.qq.com/s?__biz=MzI1ODUzNjQ1Mw==&mid=2247518136&idx=1&sn=812ec79199ae793f28770287969d0f2b&chksm=ea0462d2dd73ebc40f6ecc4f1f52fb2a3e0c798ca152aa89cc42b8e77ef6e54234695ad43025#rd", "tagid": [], "title": "肆虐非洲的“博科圣地”究竟是什么?", "update_time": 1578235905 }, { }, { } ], "base_resp": { "err_msg": "ok", "ret": 0 }} 响应的字段
app_msg_cnt 表示这个公众号已经发布了919次文章,不代表919篇文章
aid 文章唯一的id,应该是 appmsgid 代表一次群发,如三篇文章是一次性群发的,其appmsgid相同 cover 文章封面图片的url create_time 创建时间戳 digest 文章的摘要信息 is_pay_subscribe item_show_type itemidx 在这次群发中的序号 link 文章的url tagid 为一个列表 title 文章的标题 update_time 文章更新的时间戳 这些已经包含了一篇文章的元数据了。
token从哪儿来
上面的GET方法提交的参数有中都有个token字段,这个字段的用途应该鉴权用的,这个值从哪儿来的?我们在前面的HTTP请求中找,发现几乎所有的请求中的都带有这个token,我猜测这个token是用户登陆时从后端返回来的。
为了印证这个判断,重新登陆一次,发现了有这样的一个HTTP请求。 请求网址:https://mp.weixin.qq.com/cgi-bin/bizlogin?action=login 请求方法:POST 表单数据:{ "userlang": "zh_CN", "redirect_url": "", "token": "", "lang": "zh_CN", "f": "json", "ajax": "1"} 响应:
{ "base_resp": { "err_msg": "ok", "ret": 0 }, "redirect_url": "/cgi-bin/home?t=home/index&lang=zh_CN&token=1193797244"} 后端返回了一个重定向的uri,其中就包含了token的值。
完成这个请求后,页面进行了重定向,并且以后的每次请求都有会有lang=zh_CN&token=xxxx这两个参数。代码实现
完成了上面这些分析,下面我们进行代码实现。
# -*- coding:utf-8 -*-# written by wlj @2020-1-6 23:12:47 #功能:爬取一个公众号的所有历史文章存入数据库#用法:python wx_spider.py [公众号名称] 如python wx_spider.py 地球知识局import timeimport jsonimport requests,re,sysfrom requests.packages import urllib3from pymongo import MongoClienturllib3.disable_warnings()#全局变量s = requests.Session()headers = { 'User-Agent':"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:72.0) Gecko/20100101 Firefox/72.0", "Host": "mp.weixin.qq.com", 'Referer':'https://mp.weixin.qq.com/'}#cookies 字符串,这是从浏览器中拷贝出来的字符串,略过不讲cookie_str = "xxxx"cookies = { }#加载cookies,将字符串格式的cookies转化为字典形式def load_cookies(): global cookie_str,cookies for item in cookie_str.split(';'): sep_index = item.find('=') cookies[item[:sep_index]] =item[sep_index+1:]#爬虫主函数def spider(): #本地的mongodb数据库 mongo = MongoClient('127.0.0.1',27017).wx.gzh #加载cookies load_cookies() #访问官网主页 url = 'https://mp.weixin.qq.com' res = s.get(url=url,headers=headers,cookies = cookies,verify=False) if res.status_code == 200: #由于加载了cookies,相当于已经登陆了,系统作了重定义,response的url中含有我们需要的token print(res.url) #获得token token = re.findall(r'.*?token=(\d+)',res.url) if token: token = token[0] else:#没有token的话,说明cookies过时了,没有登陆成功,退出程序 print('登陆失败') return print('token',token) #检索公众号 url = 'https://mp.weixin.qq.com/cgi-bin/searchbiz' data = { "action": "search_biz", "begin": "0", "count": "5", "query": sys.argv[1], "token": token, "lang": "zh_CN", "f": "json", "ajax": "1" } res = s.get(url=url,params = data,cookies=cookies,headers=headers,verify=False) if res.status_code == 200: #搜索结果的第一个往往是最准确的 #提取它的fakeid fakeid = res.json()['list'][0]['fakeid'] print('fakeid',fakeid) page_size = 5 page_count = 1 cur_page = 1 #分页请求文章列表 while cur_page <= page_count: url = 'https://mp.weixin.qq.com/cgi-bin/appmsg' data = { "action": "list_ex", "begin": str(page_size*(cur_page-1)), "count": str(page_size), "fakeid": fakeid, "type": "9", "query": "", "token": token, "lang": "zh_CN", "f": "json", "ajax": "1" } res = s.get(url=url,params = data,cookies=cookies,headers=headers,verify=False) if res.status_code == 200: print(res.json()) print('cur_page',cur_page) #文章列表位于app_msg_list字段中 app_msg_list = res.json()['app_msg_list'] for item in app_msg_list: #通过更新时间戳获得文章的发布日期 item['post_date'] = time.strftime("%Y-%m-%d",time.localtime(int(item['update_time']))) #插入数据库,如果已经存在同aid的话,更新,不存在,插入 mongo.update_one( { 'aid':item['aid']}, { "$set":item}, upsert=True ) print(item['post_date'],item['title']) if cur_page == 1:#若是第1页,计算总的分页数 #总的日期数,每page_size天的文章为一页 app_msg_cnt = res.json()['app_msg_cnt'] print('app_msg_cnt',app_msg_cnt) #计算总的分页数 if app_msg_cnt % page_size == 0: page_count = int(app_msg_cnt / page_size) else: page_count = int(app_msg_cnt / page_size) + 1 #当前页面数+1 cur_page += 1 print('完成!') spider() 结果
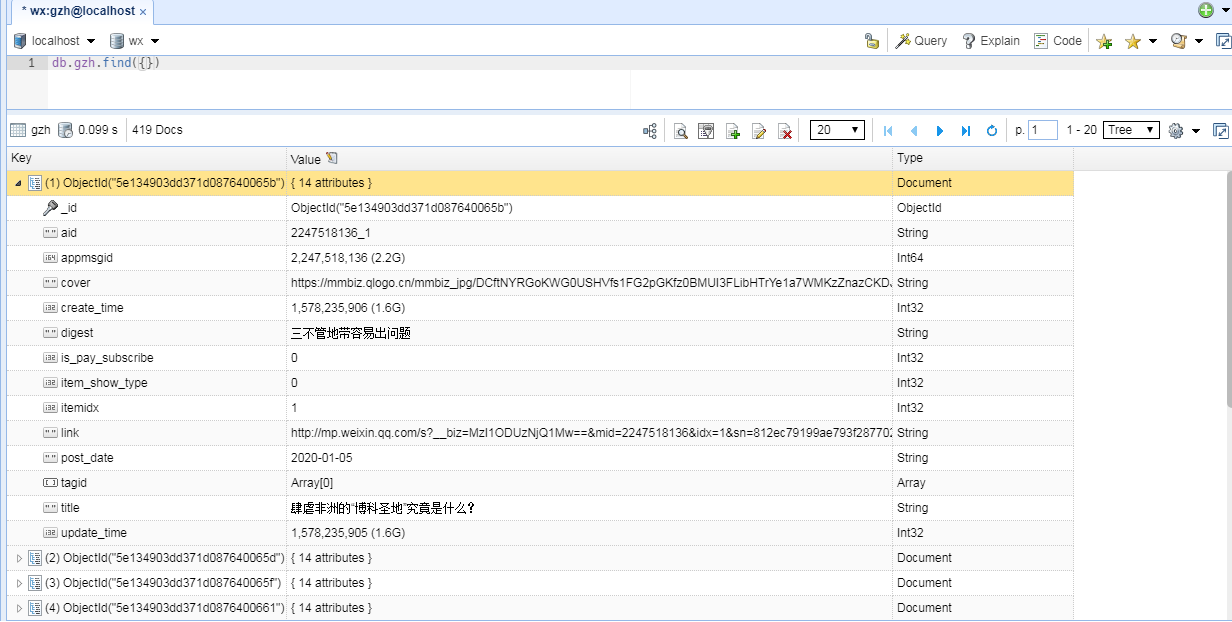
可以看到,所有文章的元数据已经存入数据库了。
下一节,我们讲如何利用文章的url来爬取文章内容,这个比较简单。 这儿还存在一个问题,腾讯的这个接口有频率限制,当爬取的次数太多,频率太快时,就请求不到数据了,会返回这样的信息。{ 'base_resp': { 'err_msg': 'freq control', 'ret': 200013}} 至少间隔一天,这个账号才能继续爬取,不知道如何破解。
转载地址:http://xhqlf.baihongyu.com/
你可能感兴趣的文章
【LEETCODE】7-Reverse Integer
查看>>
【LEETCODE】165-Compare Version Numbers
查看>>
【LEETCODE】299-Bulls and Cows
查看>>
【LEETCODE】223-Rectangle Area
查看>>
【LEETCODE】12-Integer to Roman
查看>>
【学习方法】如何分析源代码
查看>>
【LEETCODE】61- Rotate List [Python]
查看>>
【LEETCODE】143- Reorder List [Python]
查看>>
【LEETCODE】82- Remove Duplicates from Sorted List II [Python]
查看>>
【LEETCODE】86- Partition List [Python]
查看>>
【LEETCODE】147- Insertion Sort List [Python]
查看>>
【算法】- 动态规划的编织艺术
查看>>
用 TensorFlow 让你的机器人唱首原创给你听
查看>>
对比学习用 Keras 搭建 CNN RNN 等常用神经网络
查看>>
深度学习的主要应用举例
查看>>
word2vec 模型思想和代码实现
查看>>
怎样做情感分析
查看>>
用深度神经网络处理NER命名实体识别问题
查看>>
用 RNN 训练语言模型生成文本
查看>>
RNN与机器翻译
查看>>